
Schema Registry: The Common Language Between IoT and Backend
In the rapidly evolving world of the Internet of Things (IoT), seamless communication between connected devices and backend systems is the backbone of innovation. Yet, this communication hinges on a critical challenge: how can devices and backends understand each other when data structures evolve over time? Enter the Schema Registry, the unsung hero that ensures clarity, consistency, and compatibility in IoT ecosystems. At its core, a Schema Registry acts as a centralized repository for data schemas—blueprints that define the structure of payloads exchanged between IoT devices and backend services. Without it, even minor changes in data formats could lead to miscommunication, errors, or system failures. By versioning and managing these schemas, teams can decouple device development from backend logic, allowing both to evolve independently while maintaining harmony. But its role extends beyond mere storage. A Schema Registry enables backward compatibility, ensuring older devices can still communicate with updated backends, and vice versa. It also facilitates efficient routing and idempotency, guaranteeing that messages are processed exactly once, even in the face of network hiccups or retries. Whether using human-readable JSON or compact Avro, this system ensures that data remains interoperable, reliable, and scalable—the foundation for robust IoT deployments.
Schema Registry: The Common Language Between IoT and Backend
What Is a Schema Registry?
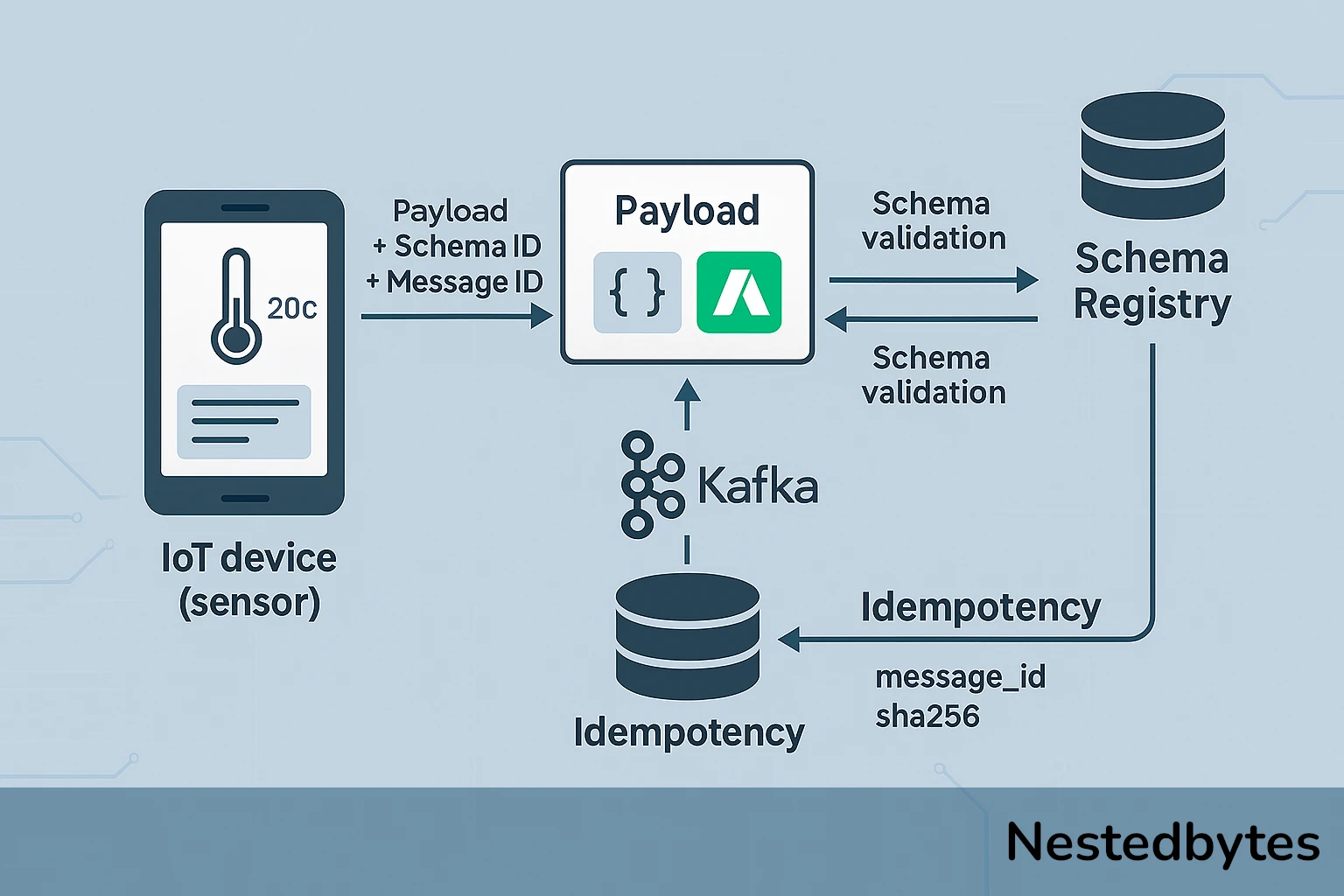
In the IoT ecosystem, communication between a connected device and its backend relies on the exchange of payloads (structured data). For this communication to be effective, both parties must understand each other perfectly. This requires a shared repository accessible to both backend teams and embedded software developers (IoT software).
This repository can take several forms:
- A Git repository: where data schemas (payload structures) are versioned like source code.
- A Device Registry (or dedicated Schema Registry): a more powerful, centralized solution often integrated with tools like Apache Kafka, Confluent, or cloud registries (AWS Glue Schema Registry, Google Cloud Pub/Sub Schema, etc.). This type of registry allows storing, versioning, and validating schemas while offering advanced features like backward compatibility and schema evolution management.
Without this repository, any change in data structure could lead to misunderstandings, decoding errors, or even system failures.
How Does the Backend Decode the Information?
For the backend to correctly decode a payload, the IoT device must include a schema identifier in its messages. This identifier (often called schema ID) is a unique reference pointing to the version of the schema stored in the Schema Registry.
Example Workflow:
- The device sends a payload with:
- The data (e.g.,
{ "temperature": 25.5, "humidity": 60 }). - A header or metadata containing the schema ID (e.g.,
schema_id: 1234).
- The data (e.g.,
- The backend retrieves the schema corresponding to ID
1234from the Schema Registry. - It uses this schema to decode and validate the payload.
Backward Compatibility
Concept and Benefits
Backward compatibility ensures that systems using older versions can still be understood by systems supporting new schema versions. This prevents service disruptions during updates.
Concrete Example:
- Schema Version 1:
{ "temperature": float } - Schema Version 2:
{ "temperature": float, "humidity": float }(adding an optional field with a default value). → A backend using V2 can still read messages from devices still on V1.
How to Evolve the Schema?
To maintain backward compatibility, follow these best practices:
- Add optional fields (never mandatory ones).
- Avoid deleting or renaming existing fields.
- Use default values for new fields.
- Document changes in the Schema Registry.
Impact on Deployment Orders
Schema management directly impacts update deployment:
- Deploy the backend first with the new schema version (so it can handle both old and new payloads).
- Update devices gradually, ensuring they send payloads compatible with both old and new schema versions.
- Monitor decoding errors during the transition.
Payload Formats: JSON, Avro, and Their Constraints
Schemas can apply to different data formats. Here’s a comparison of the two main ones:
<mui:table-metadata title=“Payload Formats Comparison” />
| Format | Advantages | Constraints | Typical Use Case |
|---|---|---|---|
| JSON | Human-readable, easy to debug. | Verbose (larger payload size). | Simple messages, rapid development. |
| Avro | Binary (compact), schema-integrated. | Less readable, requires decoding. | High-throughput IoT, network optimization. |
-
JSON:
- Ideal for simple payloads or when readability is crucial (e.g., logs, REST APIs).
- Constraint: Message size can become an issue for constrained networks (e.g., LoRaWAN, NB-IoT).
-
Avro:
- Binary format optimized for size and performance.
- Constraint: Requires a schema for decoding (hence the importance of the Schema Registry).
- Advantage: Natively includes the schema ID in its metadata, simplifying decoding.
Routing Messages Without Decoding the Payload
Using Content-Type and Schema ID
To avoid decoding every payload (resource-intensive), you can use:
Content-Type:- Indicates the format of the payload (e.g.,
application/json,application/avro). - Allows the routing service to know how to handle the message.
- Indicates the format of the payload (e.g.,
Schema-ID:- Specifies which schema version to use for decoding the payload.
- Example of HTTP header or metadata:
Content-Type: application/avro X-Schema-ID: 1234
Example Workflow:
- A message arrives with
Content-Type: application/avroandX-Schema-ID: 1234. - The router (e.g., Kafka, an API Gateway) uses this information to:
- Route the message to the correct consumer (e.g., a temperature data processing service).
- Avoid decoding the payload (performance gain).
Ensuring Unique Processing: Idempotency
Why Is It Necessary?
In a distributed system (IoT + Cloud), a message can be sent multiple times due to:
- A network disconnection (the device retries sending).
- A software bug (e.g., retry loop).
- Retransmission by a protocol like MQTT (QoS 1 or 2).
If the backend processes the same message multiple times, it can lead to:
- Duplicates in the database.
- Redundant actions (e.g., triggering the same alert twice).
Solution: Idempotency
A message is idempotent if processing it multiple times produces the same result as processing it once.
How to Implement It?
- Add a unique identifier (
message_id) in the payload metadata.- Example:
message_id: "temp-1234-20260610-1430".
- Example:
- Store processed
message_ids in a database (e.g., Redis, DynamoDB). - Check idempotency before processing:
- If the
message_idalready exists → ignore the message. - Otherwise → process the message and record its
message_id.
- If the
Example Payload with Idempotency:
{
"message_id": "temp-1234-20260610-1430",
"schema_id": 1234,
"payload": {
"temperature": 25.5,
"humidity": 60
}
}
Alternative Implementation for Idempotency
Another approach to ensuring idempotency, rather than having the device generate a unique identifier for each message, is to rely on a hash of combined data that guarantees uniqueness across the entire system. The transmitted payload can be combined with a timestamp and the device’s unique identifier to create a hash such as:
sha256(deviceId | payload | timestamp)
This combination introduces enough device-specific content to ensure message uniqueness without requiring the device to manage a separate ID generation system. This method is particularly useful in constrained environments where generating and storing unique IDs might be resource-intensive.
Conclusion: Essential Metadata
To ensure reliable, scalable, and high-performance communication between IoT devices and the backend, metadata associated with messages is essential. It enables:
- Decoding payloads using the Schema Registry and schema ID.
- Efficient routing with the Content-Type.
- Unique processing via idempotency (
message_id). - Compatibility maintenance during schema evolution.
Whether the data is in JSON (human-readable) or Avro (optimized), these principles apply universally. By adopting them, IoT and backend teams can collaborate seamlessly while ensuring the robustness and scalability of their system.


