
Schema Registry : Le Langage Commun entre l’IoT et le Backend
Dans l’univers en constante évolution de l’Internet des Objets (IoT), une communication fluide entre les appareils connectés et les systèmes backend est la clé de voûte de l’innovation. Pourtant, cette communication repose sur un défi majeur : comment les appareils et les backends peuvent-ils se comprendre lorsque les structures de données évoluent au fil du temps ? C’est là qu’intervient le Schema Registry, le héros méconnu qui garantit clarté, cohérence et compatibilité dans les écosystèmes IoT. Au cœur du système, un Schema Registry agit comme un référentiel centralisé pour les schémas de données — des plans qui définissent la structure des payloads échangés entre les appareils IoT et les services backend. Sans lui, même des modifications mineures des formats de données pourraient entraîner des incompréhensions, des erreurs ou des pannes système. En versionnant et en gérant ces schémas, les équipes peuvent découpler le développement des appareils de la logique backend, permettant à chacun d’évoluer indépendamment tout en maintenant une harmonie parfaite. Mais son rôle ne s’arrête pas là. Un Schema Registry permet la compatibilité ascendante, garantissant que les anciens appareils peuvent toujours communiquer avec des backends mis à jour, et inversement. Il facilite également le routage efficace et l’idempotence, assurant que les messages sont traités exactement une fois, même en cas de problèmes réseau ou de nouvelles tentatives. Que les données soient au format lisible JSON ou compact Avro, ce système garantit que les données restent interopérables, fiables et évolutives — les fondations d’un déploiement IoT robuste.
Schema Registry : Le Langage Commun entre l’IoT et le Backend
Qu’est-ce qu’un Schema Registry ?
Dans l’écosystème de l’IoT, la communication entre un appareil connecté et son backend repose sur l’échange de payloads (données structurées). Pour que cette communication soit efficace, les deux parties doivent se comprendre parfaitement. Cela implique l’existence d’un référentiel commun, accessible à la fois aux équipes backend et aux développeurs embarqués (software IoT).
Ce référentiel peut prendre plusieurs formes :
- Un dépôt Git : où les schémas de données (structures des payloads) sont versionnés comme du code source.
- Un Device Registry (ou Schema Registry dédié) : une solution plus puissante, centralisée et souvent intégrée à des outils comme Apache Kafka, Confluent, ou des registres cloud (AWS Glue Schema Registry, Google Cloud Pub/Sub Schema, etc.). Ce type de registre permet de stocker, versionner et valider les schémas, tout en offrant des fonctionnalités avancées comme la compatibilité ascendante ou la gestion des évolutions.
Sans ce référentiel, chaque modification de structure de données pourrait entraîner des incompréhensions, des erreurs de décodage, ou pire, des pannes système.
Comment le backend décode-t-il l’information ?
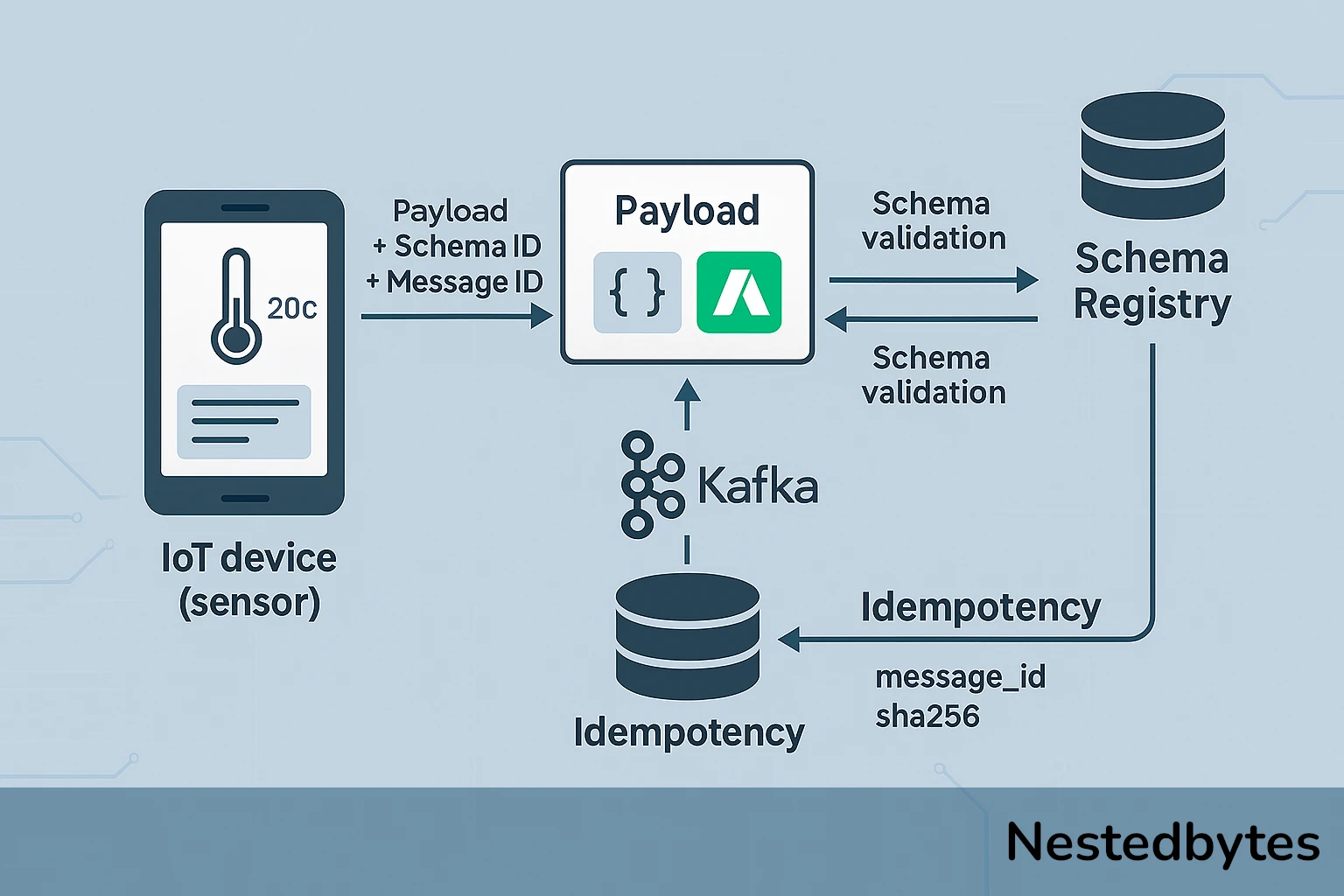
Pour que le backend puisse décoder correctement un payload, le device IoT doit inclure un identifiant de schéma dans ses messages. Cet identifiant (souvent appelé schema ID) est une référence unique pointant vers la version du schéma stockée dans le Schema Registry.
Exemple de workflow :
- Le device envoie un payload avec :
- Les données (ex. :
{ "temperature": 25.5, "humidity": 60 }). - Un en-tête ou métadonnée contenant le schema ID (ex. :
schema_id: 1234).
- Les données (ex. :
- Le backend récupère le schéma correspondant à l’ID
1234dans le Schema Registry. - Il utilise ce schéma pour décoder et valider le payload.
La compatibilité ascendante (Backward Compatibility)
Concept et intérêt
La compatibilité ascendante garantit que des systèmes utilisant des anciennes versions puissent toujours être compris par des systèmes supportant les nouvelles versions d’un schéma. Cela évite les ruptures de service lors des mises à jour.
Exemple concret :
- Version 1 du schéma :
{ "temperature": float } - Version 2 du schéma :
{ "temperature": float, "humidity": float }(ajout d’un champ optionnel avec valeur par defaut). → Un backend utilisant la V2 peut toujours lire les messages en provenance des devices toujours en V1.
Comment faire évoluer le schéma ?
Pour maintenir la compatibilité ascendante, voici les bonnes pratiques :
- Ajouter des champs optionnels (jamais obligatoires).
- Éviter de supprimer ou renommer des champs existants.
- Utiliser des valeurs par défaut pour les nouveaux champs.
- Documenter les changements dans le Schema Registry.
Impact sur les ordres de déploiement
La gestion des schémas a un impact direct sur le déploiement des mises à jour :
- Déployer d’abord le backend avec la nouvelle version du schéma (pour qu’il sache gérer les anciens et nouveaux payloads).
- Mettre à jour les devices progressivement, en s’assurant qu’ils envoient des payloads compatibles avec l’ancienne et la nouvelle version du schéma.
- Surveiller les erreurs de décodage pendant la transition.
Formats de payload : JSON, Avro et leurs contraintes
Les schémas peuvent s’appliquer à différents formats de données. Voici une comparaison des deux principaux :
| Format | Avantages | Contraintes | Cas d’usage typique |
|---|---|---|---|
| JSON | Lisible par un humain, facile à déboguer. | Verbose (taille des payloads plus grande). | Messages simples, développement rapide. |
| Avro | Binaire (compact), schéma intégré. | Moins lisible, nécessite un décodage. | IoT à haut débit, optimisation réseau. |
-
JSON :
- Idéal pour les payloads simples ou lorsque la lisibilité est cruciale (ex. : logs, API REST).
- Contrainte : La taille des messages peut devenir un problème pour les réseaux contraints (ex. : LoRaWAN, NB-IoT).
-
Avro :
- Format binaire optimisé pour la taille et la performance.
- Contrainte : Nécessite un schéma pour le décodage (d’où l’importance du Schema Registry).
- Avantage : Intègre nativement le schema ID dans ses métadonnées, ce qui simplifie le décodage.
Router les messages sans décoder le payload
Utilisation du Content-Type et du Schema ID
Pour éviter de décoder systématiquement chaque payload (coûteux en ressources), on peut utiliser :
- Le
Content-Type:- Indique le format du payload (ex. :
application/json,application/avro). - Permet au service de routage de savoir comment traiter le message.
- Indique le format du payload (ex. :
- Le
Schema-ID:- Spécifie quelle version du schéma utiliser pour décoder le payload.
- Exemple d’en-tête HTTP ou de métadonnée :
Content-Type: application/avro X-Schema-ID: 1234
Exemple de workflow :
- Un message arrive avec
Content-Type: application/avroetX-Schema-ID: 1234. - Le routeur (ex. : Kafka, un API Gateway) utilise ces informations pour :
- Acheminer le message vers le bon consommateur (ex. : un service de traitement des données de température).
- Éviter de décoder le payload (gain de performance).
Garantir l’unicité du traitement : l’idempotence
Pourquoi c’est nécessaire ?
Dans un système distribué (IoT + Cloud), un message peut être envoyé plusieurs fois à cause :
- D’une déconnexion réseau (le device réessaye l’envoi).
- D’un bug logiciel (ex. : boucle de réenvoi).
- D’une retransmission par un protocole comme MQTT (QoS 1 ou 2).
Si le backend traite le même message plusieurs fois, cela peut entraîner :
- Des duplicatas dans la base de données.
- Des actions redondantes (ex. : déclencher deux fois une alerte).
Solution : l’idempotence
Un message est idempotent si son traitement multiple produit le même résultat qu’un traitement unique.
Comment l’implémenter ?
- Ajouter un identifiant unique (
message_id) dans les métadonnées du payload.- Exemple :
message_id: "temp-1234-20260610-1430".
- Exemple :
- Stocker les
message_idtraités dans une base de données (ex. : Redis, DynamoDB). - Vérifier l’idempotence avant traitement :
- Si le
message_idexiste déjà → ignorer le message. - Sinon → traiter le message et enregistrer son
message_id.
- Si le
Exemple de payload avec idempotence :
{
"message_id": "temp-1234-20260610-1430",
"schema_id": 1234,
"payload": {
"temperature": 25.5,
"humidity": 60
}
}
Autre implémentation possible pour l’idempotence
Une autre approche pour garantir l’idempotence, plutôt que de faire générer un identifiant unique par le device pour chaque message, consiste à utiliser un hash des données combinées garantissant l’unicité dans tout le système. Les informations transmises (la payload) peuvent être associées à un timestamp et à l’identifiant unique du device pour produire un hash du type :
sha256(deviceId | payload | timestamp)
Cette combinaison apporte suffisamment de spécificité par device pour garantir l’unicité du message, sans nécessiter que le device gère un système de génération d’ID séparé. Cette méthode est particulièrement utile dans des environnements contraints où la génération et le stockage d’ID uniques pourraient être coûteux en ressources.
Conclusion : Des métadonnées indispensables
Pour assurer une communication fiable, évolutive et performante entre les devices IoT et le backend, les métadonnées associées aux messages sont indispensables. Elles permettent de :
- Décoder les payloads grâce au Schema Registry et au schema ID.
- Router efficacement les messages avec le Content-Type.
- Garantir l’unicité du traitement via l’idempotence (
message_id). - Maintenir la compatibilité lors des évolutions de schémas.
Que les données soient en JSON (lisible) ou en Avro (optimisé), ces principes s’appliquent universellement. En les adoptant, les équipes IoT et backend peuvent collaborer sereinement, tout en garantissant la robustesse et la scalabilité de leur système.


